足球游戏是一个典型的多智能体学习场景,因此谷歌足球环境(Google Research Football)自发布以来就受备受关注。但因为复杂性和计算量等问题,它在多智能体研究方面一直未能得到充分利用。目前大多数开源的代码实现都来自于Kaggle的单智能体足球竞赛,单智能体在工作时同一时间只控制一个球员,其他的10个球员是由内置bot控制,这一操控方式与FIFA游戏的操作方式类似。近来,也有一些相关工作研究了足球环境中的多智能体问题,但往往局限于简单的特定场景。作为最终挑战,11vs11场景一直以来缺少一套开源的训练框架与基准线。
今年夏天,数研院联合中科院在IEEE Conference on Game会议上,在线组织了5vs5、11vs11两个赛道的多智能体竞赛。同时,数研院也投入力量进行了该问题的研究,提供了强力的基线模型。在CoG会议比赛结束之后,我们希望能有更多的多智能体研究者和足球爱好者投入到足球AI的研究中来,一直筹备相关代码的开源工作。此次,数研院开放了一系列方便大家快速上手足球AI研究的资源,除了训练框架,还包括分析工具、基线模型等等,希望推动足球AI研究社区的进一步发展。这些内容现在开源在https://github.com/Shanghai-Digital-Brain-Laboratory/DB-Football,欢迎大家关注和加入。
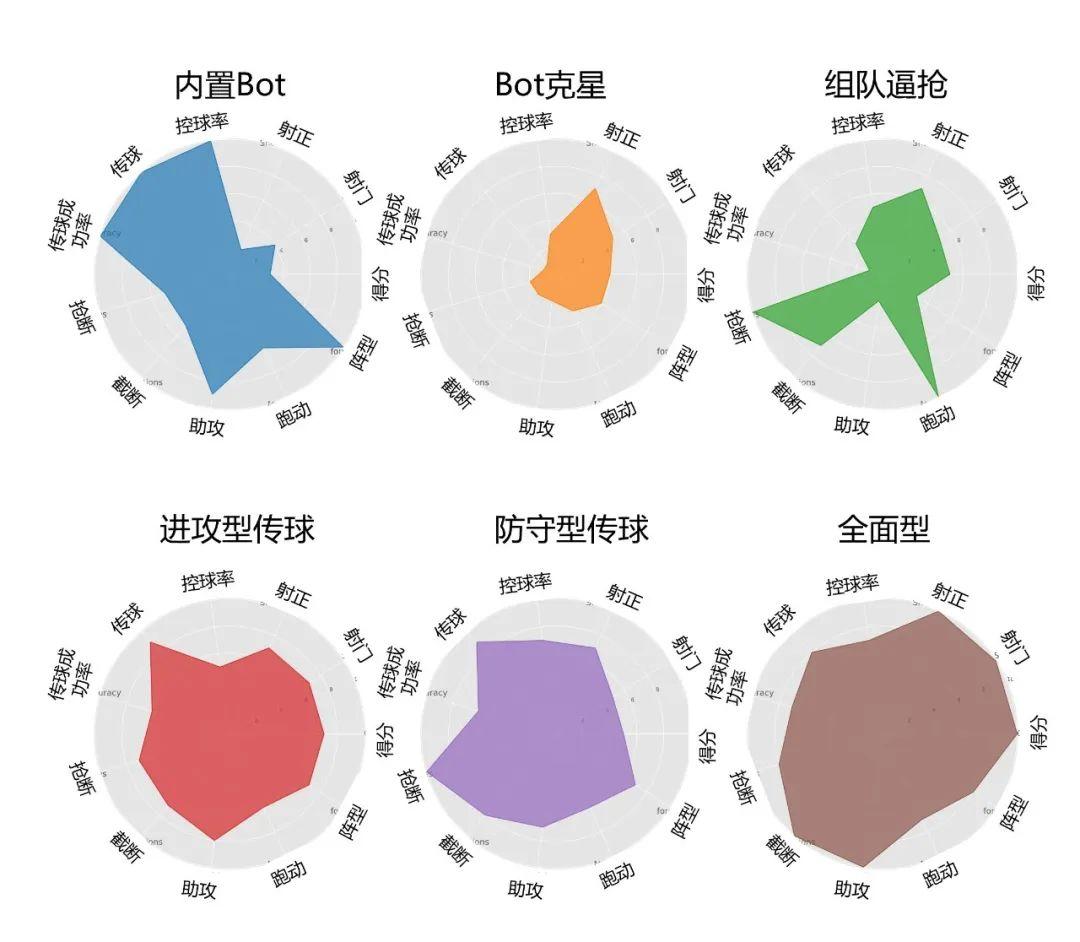
在物理世界中,一支球队的组建和训练过程是从个体到整体,自下而上的构建过程。一支优秀的球队首先要拥有在传球、射门、防守、跑位等个人技术能力上足以支撑球队战术体系的球员,然后在小团队层面形成,如撞墙配合、区域防守等局部战术配合,进而在11人完整阵容层面形成战术风格(如上文提到的Tiki-Taka等)。数研院的足球AI训练框架也是参考了这样的训练方式,把每一个球员作为一个单独的策略智能体,在个人层面上,通过提供在不同球场情况下人为设计的奖励信号来指导单个个体学习基础的行为比如带球、射门等。在此基础上,给予个体附近的队友和对手的信息,来提供小范围内的配合的可能,然后再将11个智能体组建成一支球队并一同与不同风格对手对抗来训练球队的技战术配合。
漂亮的射门
漂亮的传球配合
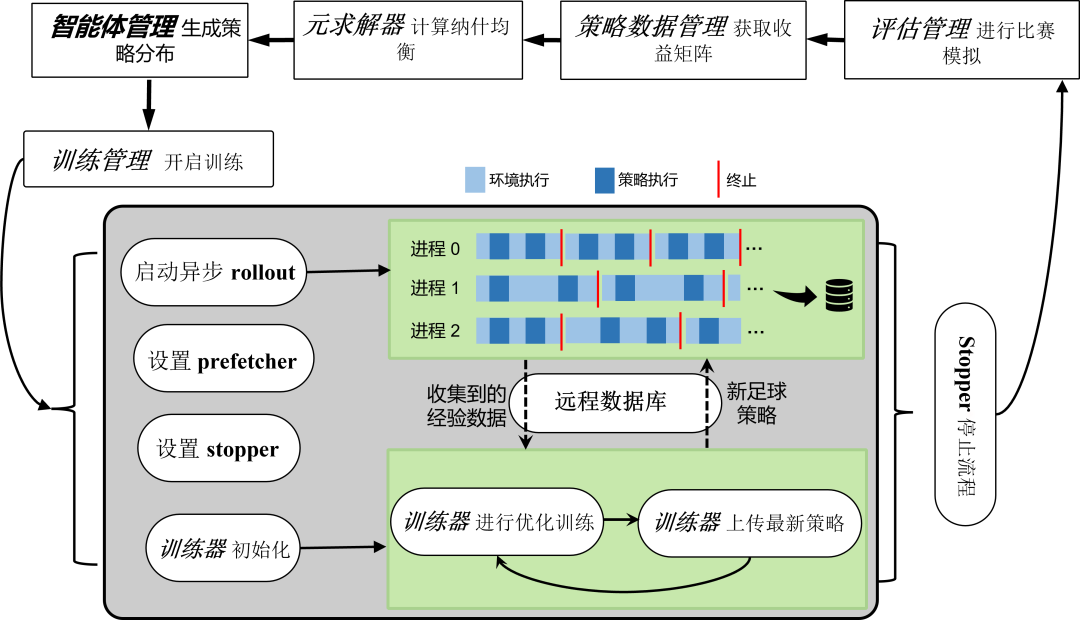
然而,足球11v11 AI 训练面临着训练量极大的问题(足球场大,同一时间控制的球员数量多),这也是很多在谷歌足球环境上做实验的一些工作面临的主要困难之一。针对这一问题,我们在MALib的基础上开发了一套轻量版本的多智能体强化学习的训练框架,并为其命名为Light-MALib。在这套训练框架下,指导队伍并行地进行对战经验收集和球队技术学习,这相当于一边比赛一边上课学习战术,大大提升了学习的效率。此外,我们关注的是如何让智能体从零开始学习,因此频繁采用了自博弈(self-play)的方式(和AlphaGo一样),让球队自我对抗,逐步开发探索出新的技能来升级。我们还设置了专门的陪练球队(exploiter in league training)从零发掘最新球队的战术漏洞,因此在自博弈的流程中,我们的球队需要同时能够打败陪练球队,避免战术上的漏洞。



 发表于 2023-1-1 16:17:57
发表于 2023-1-1 16:17:57